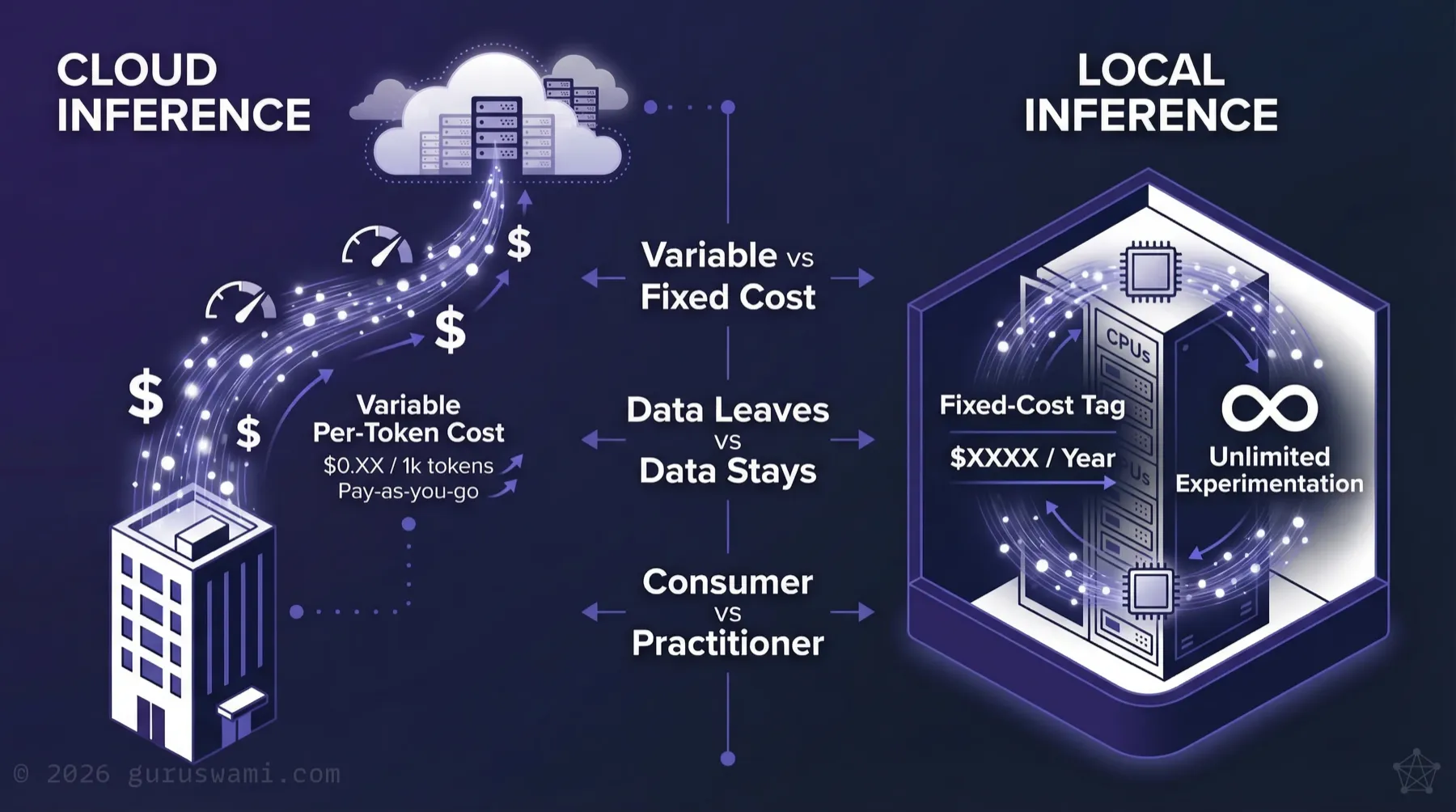
- Data sovereignty by physics, not policy. During pilots with real data, the simplest guarantee is ensuring the data never leaves the building.
- Pilot economics favour local. Cloud billing scales unpredictably. Local infrastructure means fixed costs and unlimited experimentation.
- Your best people will teach themselves. A capable machine plus permission to experiment builds more capability in three months than formal training delivers.
- Mistakes become lessons, not breaches. A developer who pastes an API key into a local model gets a learning moment. The same mistake on a cloud service is a data incident.
- Smaller models, fine-tuned for your task, outperform larger generic ones. We built a forensic accountant that runs 24/7 on a A$5,000 GPU, scrutinising other AI models for hallucinations and procedural breaches. Prompting asks a model to role-play. Fine-tuning changes what it is.
The Problem Is Not the Technology
The default advice from every systems integrator in Australia is the same: buy a cloud subscription, connect to a frontier model, and start building. GPT-4, Claude, Gemini. Pick your vendor, pay per token, and figure it out.
Cloud inference may well be the right choice for production workloads at scale. But as the starting point for pilots, team education, and innovation, it is often the wrong choice. The reasons go beyond data sovereignty. Our shadow AI brief covers what happens when data leaves your network through unmanaged tools. This one is about keeping it on-premises during the phase where your teams are learning.
The biggest limitation in AI adoption right now is not the capability of the tools. It is how development teams learn to use them. This technology domain is so new that no one fully understands it. The vendors don't. The researchers don't. Some failure modes don't even have names yet.
The innovation is possible. But getting there safely is a steep and dangerous learning curve. The steepest part isn't technical. It's translating the board's vision and risk appetite into something a development team can act on, and translating the team's technical reality back into language the board can govern. That translation layer is where most initiatives break down.
The Practical Case for Local Inference
The Sovereign AI Argument Gets Real
"Sovereign AI" in Australia is largely a marketing exercise. Most "Australian-hosted" offerings still route inference through international nodes, log prompts on overseas infrastructure, or depend on API calls to vendors who can change terms at any time.
For production workloads on non-sensitive data, cloud inference with appropriate contractual protections may be perfectly adequate. But during pilots, when your teams are experimenting with real data to understand what works, the simplest way to guarantee data sovereignty is to ensure the data never leaves the building.
Local inference on owned hardware achieves this by physics, not policy. For Defence, Intelligence, and any organisation handling protected information, this is often a hard requirement. For everyone else, it's the lowest-risk way to learn.
Pilot Economics
The reason most Australian AI initiatives stall (MIT, 2025) isn't usually technical failure. It's cost-to-value uncertainty combined with a learning curve that only shortens through hands-on experimentation.
Cloud inference bills scale unpredictably. Agentic systems that loop can generate thousands of dollars in charges overnight. Leaders can't justify ongoing spend without clear ROI, and they can't demonstrate ROI without running pilots long enough to measure.
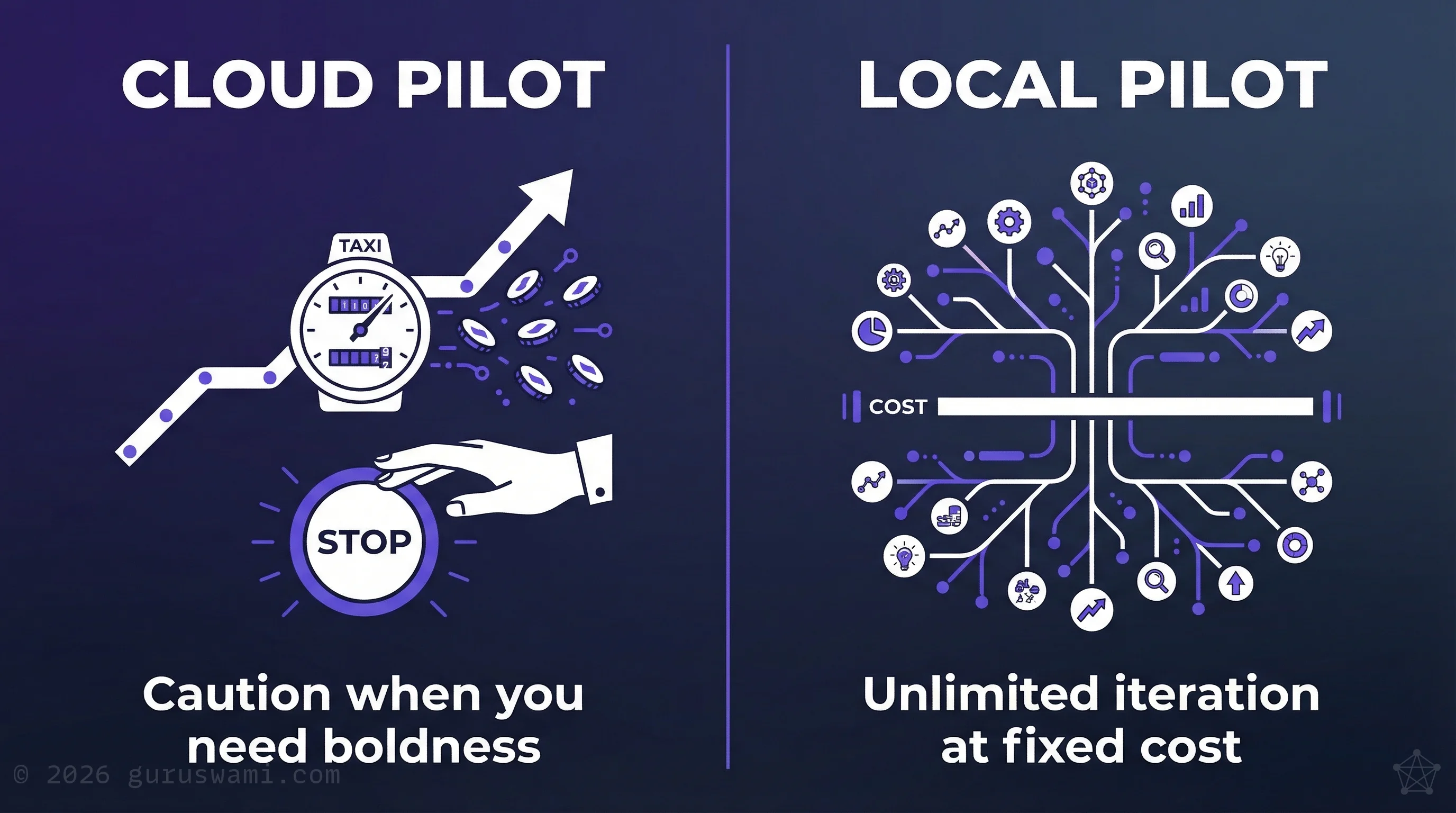
Local inference changes the economics:
- Fixed infrastructure cost rather than variable per-token billing
- Unlimited experimentation. Development teams can iterate, test, and fail fast without watching a meter
- Predictable budgets that procurement and finance can approve without open-ended exposure
This is particularly critical during pilot and education phases, where the entire point is to experiment freely and build the organisational muscle to make good decisions about AI. Metered cloud inference creates exactly the wrong incentive: caution when you need boldness.
The Honest Trade-Off
Local inference is not free. It requires capital expenditure on hardware and someone with the technical knowledge to operate it. For organisations without either, the entry cost is real. Managed on-premises options and hosted private inference services exist for organisations that lack internal engineering capacity.
For those with even modest technical capability, the cost is lower than most assume. An A$10,000 Apple Mac Studio can run open-weight models approaching frontier complexity. Slower than cloud, but with more choice of models and no vendor lock-in. A comparable Nvidia GPU cluster costs substantially more.
We do not sell hardware. We have no vendor relationships. The recommendation is simply: buy a few machines, give them to your smartest people, and let them start learning.
This is why we recommend local inference for the pilot and learning phase, not as a universal replacement for cloud. The goal is to build the knowledge to make an informed architecture decision, not to avoid cloud permanently. Some workloads will belong in the cloud. The point is to know which ones, and why, before you commit.
Unlock Your Best People
The organisations that will lead in AI are not the ones with the biggest cloud budgets. They are the ones whose internal teams understand the technology well enough to make good decisions, including when cloud deployment is the right production choice.
Running models in-house during the learning phase forces a level of technical engagement that cloud APIs deliberately abstract away. Teams learn how inference actually works, how retrieval quality affects output, how prompt engineering interacts with model behaviour. That knowledge compounds. It makes every subsequent AI decision better informed, whether the decision is to deploy locally, move to cloud, or build a hybrid architecture.
There is a human factor here that most strategies overlook. Every organisation has people who are genuinely fascinated by this technology. They read the research papers. They follow the open-source community. They experiment on their own time because they find it interesting.
Give those people a capable machine and permission to explore, and they will teach themselves more in three months than any formal training programme could deliver. They will connect with open-source researchers, test new models the week they are released, and build institutional knowledge that no vendor can sell you. The hardware is not the investment. It is the catalyst for the people who will actually build your AI capability.
The entry point can be surprisingly modest. A single Nvidia RTX 5090 sitting under a developer's desk can run a 70B parameter model, serving AI code assistance to an entire development team. Locally, safely, with no data leaving the building.
Where Mistakes Become Lessons
This does not replace the need for AI safety education, acceptable-use policies, or data handling discipline. But it creates an environment where mistakes become lessons instead of liabilities.
A developer who accidentally pastes an API key or customer PII into a local model has a learning moment they will never forget. The same mistake on a cloud service is a data breach they hope nobody notices.
You want your teams to make these mistakes early, on hardware you control, where the consequences are education rather than exposure.
Cloud inference during the pilot phase keeps teams as consumers. Local inference makes them practitioners. Practitioners make better decisions about production architecture.
The Shift Toward Smaller Models
The dominant assumption in AI for the past two years has been that bigger models are better models. The race to the largest parameter count drove investment in cloud infrastructure, because only hyperscalers could afford to run and serve frontier-scale models. Access to AI meant API subscriptions to someone else's hardware.
That assumption is breaking down.
Recent research from Meta's Llama series, Mistral, and Chinese labs including DeepSeek and Alibaba's Qwen has consistently demonstrated that smaller models, trained more carefully and matched to specific tasks, outperform larger generic ones on those tasks. A 23 billion parameter model specifically shaped for legal document review will produce better output for that task than a 200 billion parameter model prompted to do the same thing. The smaller model is faster, cheaper to run, and fits on hardware your organisation can own.
The cloud giants built their moat on scale. That moat is narrowing. The question is no longer "which API subscription gives us access to the most powerful model?" It is "which model, shaped for our specific task, running on infrastructure we control, gives us the best outcome?"
Answering that question requires practitioners: people who understand how models work, how to fine-tune them, and how to evaluate them honestly. It is not a question a vendor can answer for you. Their incentive is to keep you on their platform.
A single business process may call for multiple discrete inference tasks: retrieval from a document store, a procedure compliance check, a security audit, a verification pass against a known-good baseline. Each task is better served by a model shaped for that purpose than by a single large model asked to do everything.
We built a forensic accountant.
Not a general-purpose AI assistant. A model specifically shaped with the cognitive profile of a meticulous, detail-oriented forensic reviewer: trained to scrutinise the outputs of other AI models for hallucinations, aberrant behaviour, and procedural breaches. Its role is adversarial by design. Given an AI-generated analysis, its job is to find what is wrong with it.
It runs 24 hours a day, seven days a week, on a GPU worth A$5,000. It never takes a day off. It never loses focus at the end of a long shift. It does not have bad days or miss things because it is distracted.
Prompting asks a model to role-play a forensic accountant. Fine-tuning changes what it is. The difference in output quality, particularly on edge cases, ambiguous data, and procedural gaps, was measurable and consistent.
The model was shaped through our REAP pipeline: four stages covering reasoning extraction, evaluation, alignment, and production validation.
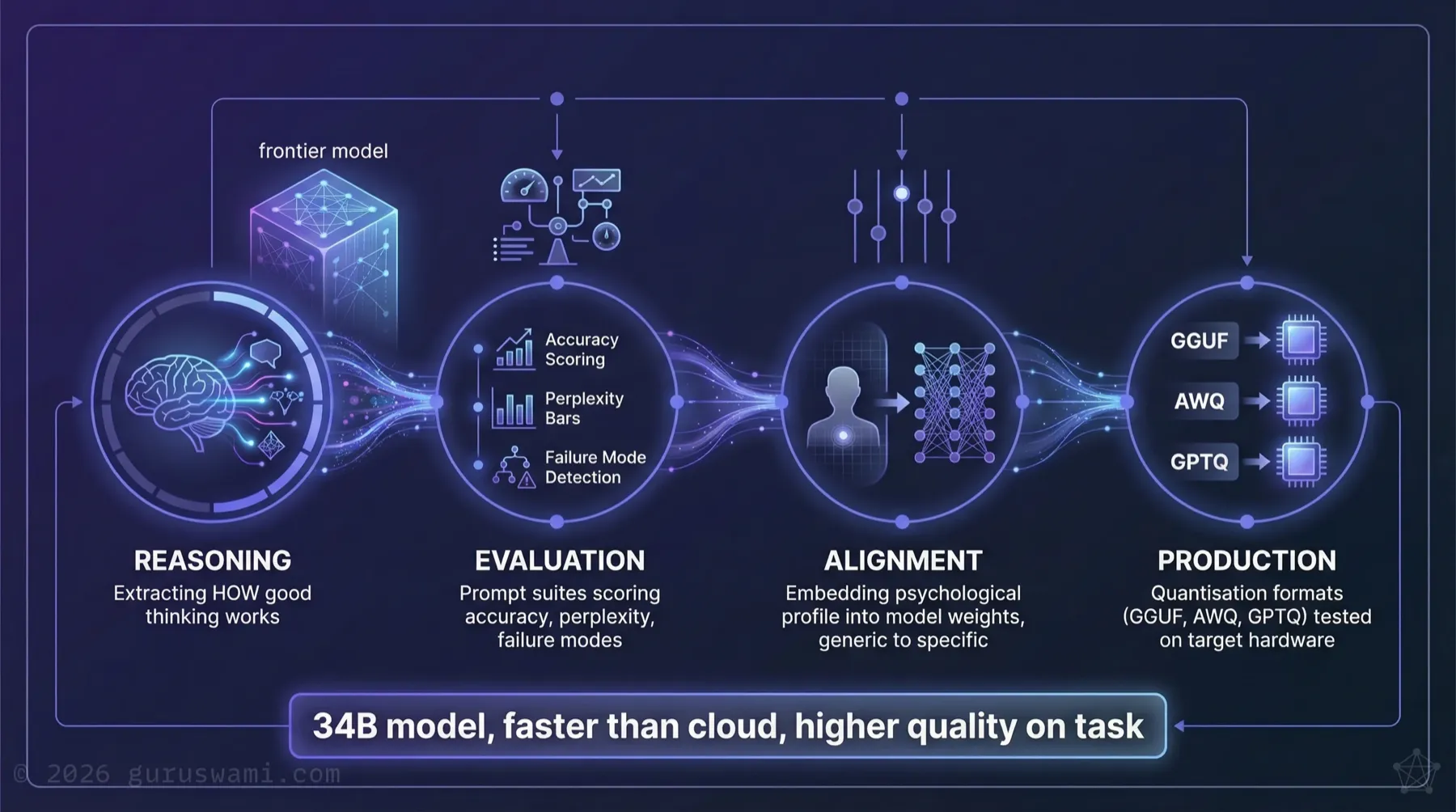
It is published on Hugging Face and available to download and run in air-gapped environments. No cloud connection required. No data leaves the building.
Building these systems requires your team to understand AI at a depth that goes well beyond subscribing to an API and maintaining a prompt library. They need to understand how models work, how to evaluate them honestly, how fine-tuning changes behaviour, and how to compose multiple models into a reliable workflow. That understanding does not come from a vendor engagement. It comes from building.
With that experience, your team can identify specific business challenges, design the inference architecture to address them, test it against real failure modes, and deploy models that run locally on your most sensitive data, without cloud costs or data sovereignty risk.
Implications for Leaders
If you are currently evaluating AI for your organisation:
Start local, scale to cloud. Use the pilot phase to build internal capability on local infrastructure. Once your team understands the technology deeply enough to make informed architecture decisions, you'll know which workloads belong in the cloud and which don't, and you'll be able to govern both.
Benchmark before you commit. Ask your vendors to benchmark their offering against a fine-tuned local model on your actual use cases, not generic benchmarks. Many will decline. That tells you something about what they're actually selling, or reveals the limits of their understanding.
Consider the pilot economics. Calculate what unrestricted local experimentation would cost versus metered cloud inference over a 90-day pilot. Factor in the learning your team gains from hands-on infrastructure. That institutional knowledge has compounding value. A $200 per month per user subscription looks cheap on a spreadsheet. Then someone pastes client PII or an API key into a cloud prompt, and you have a notifiable data breach instead of a pilot.
Invest in the translation layer. The hardest part of AI adoption isn't the technology. It's building the organisational capacity to translate between board-level vision and development-team reality. Local pilots, where your teams can experiment freely and learn from failure, accelerate this process.
Understand the regulatory trajectory. The DTA, APRA (CPS 230), and ASIC are all moving toward requirements that demand explainability, auditability, and data sovereignty. Our strategic roadmap details the specific deadlines. Architectures you can fully inspect and control are easier to govern, whether they ultimately run locally, in the cloud, or both.
- Local inference turns mistakes into lessons instead of liabilities. You want your teams to learn what goes wrong on hardware you control, not on someone else's cloud.
- Cloud inference creates the wrong incentive during pilots: caution when you need boldness. Local inference gives teams unlimited experimentation at fixed cost.
- Give your most curious people a capable machine and permission to explore. They will build institutional knowledge faster than any training programme or vendor engagement.
- The future of AI in organisations is specialised, not generalised. A business process will call multiple purpose-built models, each shaped for its task. A forensic reviewer that runs 24/7, never loses focus, and costs A$5,000 in hardware is already possible.
- Building specialised models requires practitioner depth, not a prompt library. Your team needs to understand how models work, how fine-tuning changes behaviour, and how to compose inference workflows. That understanding only comes from building.
- Start local, scale to cloud. Build the internal capability to know which workloads belong where, then make the architecture decision from a position of knowledge.
Guruswami Advisory specialises in sovereign AI architecture, air-gapped inference design, and helping organisations build the internal capability to make informed deployment decisions. Our recommendations are tested on our own R&D infrastructure before they reach your organisation.
Talk to Us Explore Our Services