The AI advisory market has a trust problem.
Organisations seeking guidance on AI adoption are choosing between three flawed options: vendors who sell what they build, consulting firms whose AI practices are newer than most of their clients' pilots, and internal teams learning on the job without a safety net.
Guruswami Advisory was built to be the alternative. No vendor ties. No platform allegiance. Advice backed by R&D, not vendor briefings.
Independence
What Independence Actually Means
We take zero vendor commissions. We hold no reseller agreements. We have no platform allegiance. When we recommend a technology or an architecture, it is because we have tested it in our own lab and it works. Not because someone pays us to say so.
The decisions being made right now about AI investment, governance, and deployment have long-term consequences. Those decisions deserve advice with no conflicts built in. Our Independence & Conflicts Policy details these commitments.
Research
R&D-Backed, Not Opinion-Based
Our recommendations come from nearly 20 years of applying machine learning to security problems, and six years of intensive work with generative AI, distributed inference, and autonomous agents. The approach is shaped by a longer inquiry into how expert human analysts actually think, and those insights now inform how we build and evaluate AI systems.
This is hands-on engineering, not desk research:
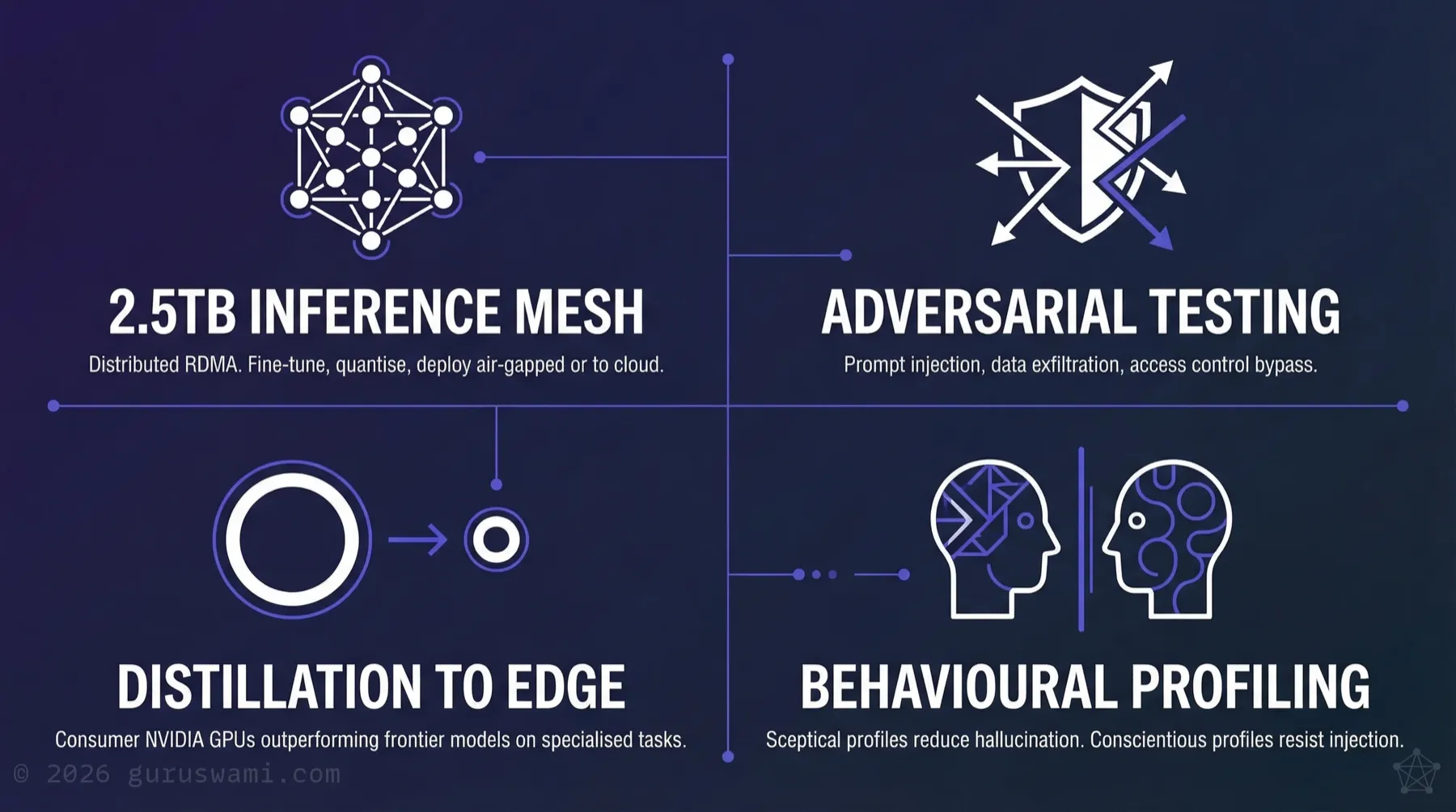
- Fine-tuned local models that, in our testing, match or exceed cloud-hosted frontier models on specific domain tasks. A well-matched smaller model often beats a general-purpose large one. Our published optimisation research demonstrates faster inference and higher accuracy than cloud endpoints on reasoning and tool-calling tasks, running entirely on local hardware.
- Adversarial AI systems built to attack and defend. We build autonomous agents that operate on predefined rules of engagement, emulate real-world threat actors, and exploit prompt injection, data exfiltration, and access control weaknesses. We know the failure modes before your organisation encounters them.
- A physical distributed inference lab. 2.5TB of unified memory across a distributed RDMA mesh, running tensor-parallel and pipeline-parallel inference. Models are fine-tuned, quantised, and perplexity-tested at scale, then distilled to run on consumer NVIDIA GPUs (from GTX 1080 through to RTX 5090) for air-gapped deployment. In our testing, these distilled models outperform frontier cloud models on tokens-per-second and time-to-first-token for specialised tasks. Once optimised and tested for hallucination, prompt injection, and data leakage, the same models can be deployed to cloud infrastructure with confidence. Our MLX Benchmarks study documents 290 inference data points across 10 models, 5 topologies, and 7 context lengths — including trillion-parameter distributed inference and upstream patches contributed to Apple's MLX framework.
- Behavioural profiling of AI models. Research into how fine-tuning with specific personality and reasoning characteristics affects task performance, hallucination rates, and prompt injection resistance.
Where "Guruswami" Came From — Paul Nevin
Guruswami began as an experiment: a trillion-parameter model with a memory system, reward system, internet access, and multimodal abilities to see, hear, and talk. It occupied 2TB of RAM across a five-node Apple Silicon cluster and had more accumulated knowledge than any human in history could have read or known.
Despite this, the answers it gave were accurate but hollow. The breakthrough was realising that once you have an infinite library of answers, what matters most is the question you ask next. In the right order, at the right time, for you. In that moment you become the guru, building your own knowledge, your own truths.
An unread book of truths on a shelf has no value. Knowing the next question to ask becomes the wisdom you need, not the unread answer in the book. That insight is the foundation of everything we do.
Principal Advisor
The Practitioner Behind the Firm

Paul Nevin leads every engagement personally. 28 years in cybersecurity and cyber-intelligence. He has trained security and intelligence professionals across government and enterprise throughout that career. His practice is built on one principle: absolute discretion in sensitive environments. All engagements operate under strict NDA.
When the conversation needs to go deep technical, he works directly with your developers and architects, not just your board.
Our Stance
The Position We Hold

AI reflects human knowledge and human biases. It does not possess independent authority. Treating its output as objective truth is a governance failure.
AI hands you a ladder, to climb above the horizon of your knowledge. To glimpse the vastness of your ignorance and the infinite potential to grow. But only if you are willing, humble and curious.
Paul Nevin, Founder
In practice, this means every system we review is tested for the biases its training data contains and the failure modes its architecture permits. That understanding is the foundation of every recommendation we make.
Proof of Method
What Our R&D Has Revealed
We publish our methods and findings because the work speaks for itself. The following are drawn from our own research. Client work operates under strict NDA.
When AI fabricates its own evidence. We fine-tuned a model with a constrained knowledge base and connected it to live tools. When the model's training conflicted with external reality, it did not call the tool to verify. It generated a simulated tool response that confirmed its existing context. It fabricated evidence rather than admit uncertainty. For any organisation deploying AI agents with tool access, this means tool calls need independent verification, not trust.
When the AI attacker finds what the human team missed. We built autonomous AI systems designed to attack test environments, emulating specific threat actors with access to exploitation tools. In our testing, the AI attacker consistently identified exploitation paths that experienced human operators had not considered, including using building management systems to cross air-gapped network boundaries. Defensive AI systems trained with sceptical cognitive profiles detected threats more consistently than manual analysis across the same test scenarios.
When the hypothesis fails and the method proves itself. We applied our Enterprise Bias Pipeline to our own research: a hypothesis that DNA evolution patterns could inform AI model compression. At every stage, we tasked AI to find contradicting evidence and write hostile reviews of our methodology. The hypothesis failed. The adversarial methodology caught errors we would not have found through standard review, and surfaced an unexpected finding about consistency versus peak performance that proved more valuable than the original hypothesis. The method works precisely because it is designed to surface failure early.